
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- toolnode
- langgraph
- rl
- 강화학습
- Python
- Ai
- 밑바닥부터 시작하는 딥러닝
- agenticrag
- tool_calls
- removemessage
- LangChain
- 강화학습의 수학적 기초와 알고리듬 이해
- 강화학습의 수학적 기초와 알고리듬의 이해
- fastapi
- adaptive_rag
- 밑바닥부터시작하는딥러닝 #딥러닝 #머신러닝 #신경망
- conditional_edges
- tool_call_chunks
- chat_history
- pinecone
- langgrpah
- update_state
- subgraph
- REACT
- RecSys
- summarize_chat_history
- add_subgraph
- rag
- Docker
- 추천시스템
- Today
- Total
타임트리
[LangGraph] Adaptive RAG 본문
Adaptive RAG
일반적인 RAG (흔히 말하는 Naive RAG 혹은 Advanced RAG)의 경우, 개발자가 전체적인 흐름을 정의하게 된다. 그리고 해당 흐름은 고정되어 있다.
아래와 같은 그래프의 경우 일반적인 RAG의 흐름이다. 아래 흐름에서는 우선 문서를 검색해서 가져온다. 그리고 문서의 연관성을 판단한 뒤, 만약 질문과 연관있는 문서가 retrieve되지 않았다면, 쿼리를 재작성하고 새로 작성된 쿼리로 문서를 가져온다.
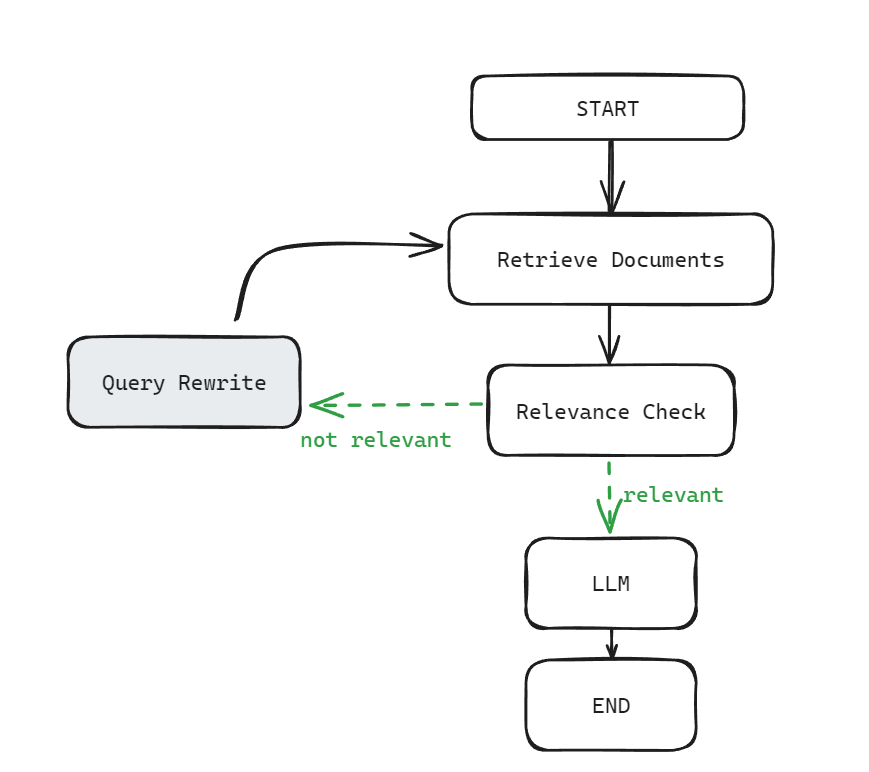
다시 생각해보면, 위 흐름은 고정되어 있기 때문에 질문이 들어오면 해당 질문을 토대로 무조건 문서를 가져오게 된다. 즉, 벡터스토어로부터 문서를 검색하는 선택지 이외의 web search가 필요한지 여부 혹은 바로 LLM의 답변이 필요한지 여부는 고려하지 않는다. 이럴 경우, 불필요한 과정을 거치게 되므로 시간 그리고 임베딩 비용 등 불필요한 비용이 발생한다.
이런 경우, 좀 더 유연하고 효율적인 해결책은 두 가지로 생각해볼 수 있다.
- Agent를 사용하지 않고, 라우터를 구현
- Agent를 사용해서 LLM이 도구 사용 여부를 결정하도록 구현
앞서서는 2번에 해당하는 Agentic RAG를 구현해봤다. 이번에는 1번에 해당하는 Adaptive RAG를 랭그래프로 구현해보자!
여기서 구현할 Adaptive RAG는 크게 2단계로 이루어진다.

- 쿼리 분석(Query Analysis): 주어진 쿼리를 필요한 경로로 라우팅
- RAG + Self-reflection: 검색한 문서 중 연관있는 문서만 추리고, 연관 있는 문서가 없다면 쿼리 재작성을, 연관 있는 문서가 있다면 답변 생성 후 할루시네이션 검사/답변과 질문 간 연관성 검사 등을 반복하며 답변의 품질을 높이는 방법
즉, LLM이 스스로 주어진 쿼리로부터 Tool의 사용 여부를 결정했던 Agentic RAG와 달리, Adaptive RAG는 각 경로를 독립적으로 구성하고, 주어진 쿼리만을 먼저 분석해서 필요한 경로로 라우팅한다. 즉, 보다 정형화된 output을 받아볼 수 있다는 점이 다르다. (high controllability)
실제 논문(https://arxiv.org/abs/2403.14403)에서는 쿼리 복잡도 분석을 위한 small model을 사용하지만, 여기서는 GPT에 해당 task를 맡기고 task로는 web search와 self-corrective RAG 2개의 경로로 라우팅하자.
1. chain 구현
router_chain
먼저 라우팅을 위한 chain router_chain을 정의하자. 라우팅을 위한 프롬프트에는 블로그 내 랭그래프 글에 대한 설명이라면 vectorstore를, 아니면 web-search를 반환하도록 하는 내용을 포함했다.
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
# 라우팅을 위한 출력형식 정의
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
source: Literal["vectorstore", "web_search"] = Field(
description="Given a user question choose to route it web search or a vectorstore"
)
system = """You are an expert at routing a user question to a vectorstore or web search.
The vectorstore ONLY contains documents related to related to parallel node processing and multiturn processing in LangGraph.
Use the vectorstore for questions on these topics. Otherwise, use web-search."""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-4o")
llm_router = llm.with_structured_output(RouteQuery)
router_chain = route_prompt | llm_routervectorstore에 저장된 내용은 랭그래프를 사용해 멀티턴과 병렬 노드 구현 방법이므로 랭그래프를 서빙하는 내용은 나와있지 않다. 따라서, 의도한대로 grader_chain이 연관성 체크에서 no를 반환한다.
## test
question = "랭그래프 병렬 노드"
print(router_chain.invoke({"question": question}))
print(router_chain.invoke({"question": "랭그래프 서빙"}))source='vectorstore'
source='web_search'grader_chain
이번에는 가져온 문서와 사용자 query 간 연관성을 확인하는 grader_chain을 정의하자. 추후 이 chain으로는 이전의 Agentic RAG에서 구현한 relevance checker는 전체 문서와 query간 연관성을 본다면, 여기서는 각 문서와 query간 연관성을 확인하고 연관있는 문서만 남기는 방식으로 구현할 예정이다.
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documetns."""
binary_score: Literal["yes", "no"] = Field(
description="Document are relevant to the question, 'yes' or 'no'."
)
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
If the document contains semantic meaning related to the user question, grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
llm_grader = llm.with_structured_output(GradeDocuments)
grader_chain = grade_prompt | llm_grader
grader_chain으로 가져온 각 문서들에 대해 user query와의 연관성 확인을 할 것이기 때문에, 아래처럼 테스트해보자. vector store에는 랭그래프를 사용한 멀티턴 구현과 병렬 노드 구현에 대한 내용만 갖고 있고 랭그래프 서빙에 대해서는 갖고 있지 않다. 따라서, question2에 대해서 가져온 문서가 의도대로 질문과 문서의 연관성이 없다고 잘 판단하고 있다.
## test
question = "랭그래프 병렬 노드"
docs = retriever.invoke(question)
doc1 = docs[0].page_content
print(grader_chain.invoke({"document": doc1, "question": question}))
question2 = "랭그래프 서빙"
docs = retriever.invoke(question2)
doc2 = docs[2].page_content
print(grader_chain.invoke({"document": doc2, "question": question}))binary_score='yes'
binary_score='no'generator_chain
다음으로, 질문과 연관있는 문서가 존재할 때, 해당 문서와 사용자 질문을 받아 답변을 생성하는 generator_chain을 정의하자.
from typing import List
from langchain.schema import Document
from langchain_core.prompts import ChatPromptTemplate
def format_docs(docs: List[Document]) -> str:
return "\n".join(
[
f"<document><content>{doc.page_content}</content><source>{doc.metadata['source']}</source></document>"
for doc in docs
]
)
template = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
When answering, be sure to credit which retrieved context you used. Answer in Korean.
Question: {question}
Context: {context}
Answer:"""
generate_prompt = ChatPromptTemplate([("human", template)])
llm_generator = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# define chain
generator_chain = generate_prompt | llm_generator
주어진 context를 기반으로 답변하며, 출처까지 의도대로 잘 반환하고 있다.
## test
generation = generator_chain.invoke(
{"question": question, "context": format_docs(docs)}
).content
print(generation)랭그래프 병렬 노드는 여러 작업을 동시에 실행할 수 있는 구조를 의미합니다. 이와 관련된 정보는 [LangGraph]의 최근 게시물에서 확인할 수 있습니다. 더 자세한 내용은 해당 링크를 참조하세요: https://sean-j.tistory.com/entry/LangGraph-Branches-for-parallel-node-execution.hallucination_checker_chain
다음으로는 LLM이 응답 시 주어진 context만을 참고한 것이 아니라 환각 현상이 발생했는지 검사하는 hallucination_checker_chain을 정의하자. 마찬가지로 이 역시 LLM을 통해 검사한다.
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Fact-based answers that refer to the given context, 'yes' or 'no'"
)
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
llm_hallucination_checker = llm.with_structured_output(GradeHallucinations)
hallucination_checker_chain = hallucination_prompt | llm_hallucination_checker
위에서 생성한 답변을 담고 있는 generation은 검색된 문서로 할루시네이션 없이 생성된 답변임을 눈으로 확인했다.
## test
hallucination_checker_chain.invoke(
{"generation": generation, "documents": format_docs(docs)}
)GradeHallucinations(binary_score='yes')answer_grader_chain
이번에는 LLM이 만들어낸 답변이 정말 user query에 적합한 답변인지 확인하는 answer_grader_chain을 정의한다.
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
system = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
answer_grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
llm_answer_grader = llm.with_structured_output(GradeAnswer)
answer_grader_chain = answer_grade_prompt | llm_answer_grader## test
answer_grader_chain.invoke({"question": question, "generation": generation})GradeAnswer(binary_score='yes')query_rewriter_chain
마지막으로, 연관 있는 문서가 없거나 답변이 사용자 query에 적합하지 않은 경우 새로운 문서를 검색해오기 위한 chain인 query_rewriter_chain을 정의하자.
from langchain_core.output_parsers import StrOutputParser
system = """You a question re-writer that converts an input question to a better version that is optimized \n
for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning.
더 나은 question을 위해 영어로의 변환도 고려해주세요."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})
주어진 쿼리를 의도가 명확하게 변환해주었다 (물론 langgraph가 아닌 rank graph라고 번역했지만..)
'What are the characteristics and applications of parallel nodes in a rank graph?'2. 상태 정의
3개의 key (question, generation, docuement)로 이루어진 State를 정의하자.
from typing import Annotated, TypedDict
from langgraph.graph.message import add_messages
class State(TypedDict):
generation: Annotated[str, "LLM answer"]
question: Annotated[str, "user question"]
documents: Annotated[list, "filtered documents"]3. 노드 정의
맨 앞단에서 router_chain이 판단한 결과 ("vectorstore" or "web-search")를 바탕으로, 2개의 큰 path를 정의한다. 이때 하나는 RAG + self-reflection이고 하나는 Web Search 이므로 이들에 필요한 노드를 각각 정의하자.
from langchain_community.tools.tavily_search import TavilySearchResults
# * RAG + self-reflection
# retrieve node
def retrieve(state: State):
print("--- [RETRIEVE] ---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents}
# 문서 필터링
def grade_documents(state: State):
"""
retrieved documents가 user query와 연관 있는지 확인 후, 연관 있는 문서만 남김
"""
print("--- [CHECK DOCUMENT RELEVANCE] ---")
question = state["question"]
documents = state["documents"]
# 각 문서에 대한 평가
filtered_docs = []
for doc in documents:
score = grader_chain.invoke(
{"document": doc, "question": question}
).binary_score
if score == "yes":
print(" --- SCORE: DOCUMENT RELEVANT")
filtered_docs.append(doc)
else:
print(" --- SCORE: DOCUMENT NOT RELEVANT")
continue
return {"documents": filtered_docs}
# 답변 생성
def generate(state: State):
print("--- [GENERATE] ---")
question = state["question"]
retrieved_docs = state["documents"]
context = format_docs(retrieved_docs)
response = generator_chain.invoke({"question": question, "context": context})
return {"generation": response.content}
# 쿼리 재작성
def rewrite_query(state: State):
print("--- [REWRITE QUERY] ---")
question = state["question"]
rewritten_query = question_rewriter.invoke({"question": question})
return {"question": rewrite_query.content}
# * Web Search
# 웹검색 노드
web_search_tool = TavilySearchResults(k=3)
def web_search(state: State):
print("--- [WEB SEARCH] ---")
question = state["question"]
web_results = []
docs = web_search_tool.invoke(question)
for doc in docs:
web_results.append(
Document(page_content=doc["content"], metadata={"source": doc["url"]})
)
return {"documents": web_results}4. Edge 정의
이번에는 조건부 분기를 위한 edge들에 사용될 함수들을 정의하자. 먼저 사용자 쿼리를 라우팅하는 route_question 함수가 필요하다.
두번째로 grade_documents노드의 결과로 만약 State의 documents에 user query와 관련 있는 문서가 없다면 쿼리를 재작성하도록 분기하는 decide_to_generate함수가 있어야 한다.
마지막으로, 할루시네이션이 발생했는지 확인하고 만약 발생했다면 다시 답변 생성을, 할루시네이션이 발생하지는 않았지만 user query에 적합한 답변이 아니라면 쿼리를 재작성하도록 분기하는 grade_generation_v_document_question 함수를 정의하자.
def route_question(state: State):
print("--- [ROUTE QUESTION] ---")
question = state["question"]
source = router_chain.invoke({"question": question})
if source.source == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web"
elif source.source == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state: State):
print("--- [ASSESS GRADED DOCUMENTS] ---")
documents = state["documents"]
# 만약 연관 있는 문서가 없다면 쿼리 재작성, 있다면 다음 노드로 진행
if not documents:
print(" --- [ALL DOCUMENTS ARE NOT RELEVANT] ---")
return "rewrite_query"
else:
print(" --- [DECISION: GENERATE] ---")
return "generate"
def grade_generation_v_document_question(state: State):
question = state["question"]
generation = state["generation"]
docs = state["documents"]
score = hallucination_checker_chain.invoke(
{"generation": generation, "documents": format_docs(docs)}
).binary_score
if score == "yes": # not hallucination
print("--- [NOT HALLUCIATION] ---")
answer_score = answer_grader_chain.invoke(
{"question": question, "generation": generation}
).binary_score
if answer_score == "yes":
print("--- [GENERATION ADDRESSES QUESTION] ---")
return "useful"
else:
print("--- [GENERATION DOES NOT ADDRESSE QUESTION] ---")
return "not useful"
else: # hallucination
print("--- [HALLUCINATION] ---")
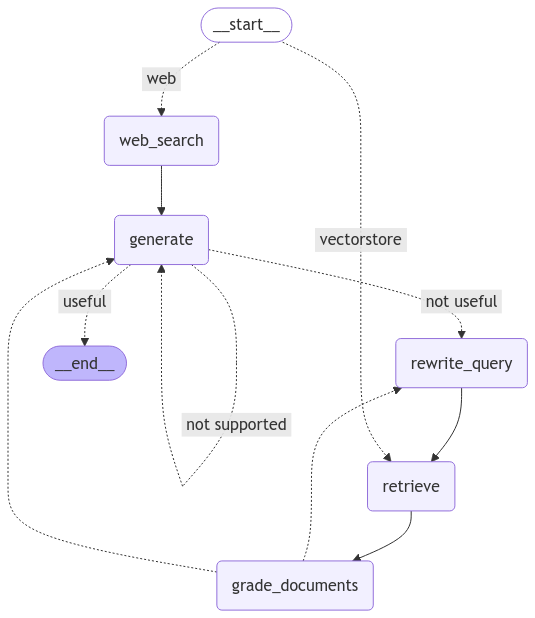
return "not supported"5. 그래프 정의
마지막으로 그래프를 정의하자. 앞에서 Node 및 Edge에 필요한 조건부 함수를 모두 정의했기 때문에 의도한대로 조립만 잘 해주면 된다!
from langgraph.graph import StateGraph, START, END
flow = StateGraph(State)
flow.add_node("retrieve", retrieve)
flow.add_node("grade_documents", grade_documents)
flow.add_node("generate", generate)
flow.add_node("rewrite_query", rewrite_query)
flow.add_node("web_search", web_search)
flow.add_conditional_edges(
START, route_question, {"web": "web_search", "vectorstore": "retrieve"}
)
# * Web Search
flow.add_edge("web_search", "generate")
# * RAG + Self-reflection
flow.add_edge("retrieve", "grade_documents")
# 각 문서를 평가한 뒤, 문서가 남아있는지에 대해 분기
flow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{"rewrite_query": "rewrite_query", "generate": "generate"},
)
flow.add_edge("rewrite_query", "retrieve")
flow.add_conditional_edges(
"generate",
grade_generation_v_document_question,
{"useful": END, "not useful": "rewrite_query", "not supported": "generate"},
)
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
graph = flow.compile(checkpointer=memory)
결과 확인
이제 의도한대로 그래프가 잘 작동하는지 확인해보자. 이를 위해 아래처럼 출력 확인을 위한 stream_graph를 정의하고 재사용하자.
import pprint
def stream_graph(inputs, config, exclude_node=[]):
for output in graph.stream(inputs, config, stream_mode="updates"):
for k, v in output.items():
if k not in exclude_node:
pprint.pprint(f"Output from node '{k}':")
pprint.pprint("---")
pprint.pprint(v, indent=2, width=80, depth=None)
pprint.pprint("\n---\n")Case1. web search
손흥민의 이번 시즌 공격 포인트는 랭그래프를 담고 있는 vector store가 아니라 웹 검색으로 넘어가야 한다. 결과를 보면, web search → 답변 생성 → 할루시네이션 확인 → 답변 연관성 확인 후 답변을 잘 반환하고 있다.
# Case 1.
config = {"configurable": {"thread_id": "1"}}
inputs = {"question": "손흥민의 이번 시즌 공격 포인트"}
stream_graph(inputs, config)--- [ROUTE QUESTION] ---
---ROUTE QUESTION TO WEB SEARCH---
--- [WEB SEARCH] ---
"Output from node 'web_search':"
'---'
{ 'documents': [ Document(metadata={'source': 'https://www.yna.co.kr/view/AKR20240310050551007'}, page_content='이번 시즌 리그에서만 14골 8도움을 올린 손흥민의 시즌 공격 포인트는 22개가 됐다. 리그 득점 순위에서 손흥민은 선두 엘링 홀란(맨체스터 시티·18골)에게 4골 뒤진 공동 4위에 이름을 올렸고, 도움 순위에선 공동 1위와 2개 차인 공동 6위다.'),
Document(metadata={'source': 'https://news.sbs.co.kr/news/endPage.do?news_id=N1007566513'}, page_content='이번 시즌 리그에서만 14골 8도움을 올린 손흥민의 시즌 공격 포인트는 22개가 됐습니다. 아울러 손흥민은 2016-2017시즌부터 8시즌 연속으로 공식전'),
Document(metadata={'source': 'https://www.hani.co.kr/arti/sports/soccer/1131687.html'}, page_content='이번 시즌 리그에서만 14골 8도움을 올린 손흥민의 시즌 공격 포인트는 22개가 됐다. 손흥민이 공식전에서 공격 포인트 20개를 넘어선 건 2016∼2017'),
Document(metadata={'source': 'https://www.yna.co.kr/view/AKR20240311045800007'}, page_content='이번 시즌 리그에서 총 14골 8어시스트를 올린 손흥민은 공격 포인트 20개도 돌파했다. 2016-2017시즌부터 8시즌 연속이다. 다른 공식전을 빼고 리그로만 한정 지으면 2021-2022시즌(23골 9어시스트) 이후 2년 만에 20개 이상 공격 포인트를 만들어냈다.'),
Document(metadata={'source': 'https://www.segye.com/newsView/20240311515649'}, page_content='손흥민의 이번 시즌 리그 14호골이자 2경기 연속 골. 손흥민은 종료 직전인 후반 49분엔 페널티 박스 왼쪽 지역에서 티모 베르너의 득점을 도우며 팀의 4번째 골을 합작했다. ... 시즌 공격 포인트 22개를 완성했다. 공식전(컵 대회 포함)에서 공격 포인트 20개 이상을')]}
'\n---\n'
--- [GENERATE] ---
--- [NOT HALLUCIATION] ---
--- [GENERATION ADDRESSES QUESTION] ---
"Output from node 'generate':"
'---'
{ 'generation': '손흥민의 이번 시즌 공격 포인트는 22개입니다. 그는 리그에서 14골과 8도움을 기록했습니다. (출처: '
'https://www.yna.co.kr/view/AKR20240310050551007)'}
'\n---\n'Case2. vector store
이번에는 랭그래프의 병렬 노드 구성과 관련한 용어인 fan-in 과 fan-out에 대해 물어봤다. vector store에는 랭그래프의 멀티턴, 병렬 노드에 대한 블로그 글을 저장하고 있으므로 vector store로 라우팅 되고 이후 문서-쿼리 연관성 확인 → 답변 생성 → 할루시네이션 확인 → 답변-쿼리 연관성 확인의 절차를 거쳐 답변을 반환하고 있다.
(여기서, 출력이 많은 retrieve, grade_documents의 결과를 출력하지 않도록 했다)
config = {"configurable": {"thread_id": "2"}}
inputs = {"question": "랭그래프에서 fan in, fan out의 의미"}
stream_graph(inputs, config, exclude_node=["retrieve", "grade_documents"])--- [ROUTE QUESTION] ---
---ROUTE QUESTION TO RAG---
--- [RETRIEVE] ---
'\n---\n'
--- [CHECK DOCUMENT RELEVANCE] ---
--- SCORE: DOCUMENT RELEVANT
--- SCORE: DOCUMENT RELEVANT
--- SCORE: DOCUMENT RELEVANT
--- SCORE: DOCUMENT RELEVANT
--- [ASSESS GRADED DOCUMENTS] ---
--- [DECISION: GENERATE] ---
'\n---\n'
--- [GENERATE] ---
--- [NOT HALLUCIATION] ---
--- [GENERATION ADDRESSES QUESTION] ---
"Output from node 'generate':"
'---'
{ 'generation': '랭그래프에서 fan-out은 병렬 처리를 위해 여러 노드로 흩어지는 과정을 의미하고, fan-in은 병렬 '
'처리가 끝난 후 결과가 합쳐지는 구간을 말합니다. 예를 들어, A 노드에서 B, C, D 노드로 '
'fan-out한 후 E 노드로 합쳐지는 것이 fan-in입니다. (출처: '
'https://sean-j.tistory.com/entry/LangGraph-Branches-for-parallel-node-execution)'}
'\n---\n'
---
출처:
LangGraph. "Adaptive RAG". https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_adaptive_rag/
'LLM > LangGraph' 카테고리의 다른 글
| [LangGraph] 요구사항 연속적으로 수집하기 (prompt generation) (0) | 2025.01.29 |
|---|---|
| [LangGraph] Agentic RAG (0) | 2025.01.28 |
| [LangGraph] Subgraph State(상태) (0) | 2025.01.02 |
| [LangGraph] - Subgraph(서브그래프) 1 (0) | 2025.01.01 |
| [LangGraph] 과거 대화 이력의 요약 (0) | 2025.01.01 |



