
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Ai
- REACT
- agenticrag
- 밑바닥부터시작하는딥러닝 #딥러닝 #머신러닝 #신경망
- add_subgraph
- langgraph
- tool_call_chunks
- tool_calls
- summarize_chat_history
- 강화학습의 수학적 기초와 알고리듬의 이해
- RecSys
- Docker
- adaptive_rag
- 강화학습
- 추천시스템
- LangChain
- toolnode
- update_state
- langgrpah
- rag
- removemessage
- rl
- 강화학습의 수학적 기초와 알고리듬 이해
- Python
- 밑바닥부터 시작하는 딥러닝
- chat_history
- fastapi
- subgraph
- pinecone
- conditional_edges
- Today
- Total
타임트리
Week6. MDP-2 본문
지금까지 살펴봤던 내용들을 간단하게 정리해보자. MDP는 동적계획법 중 확률적 동적계획법의 특별한 경우에 속한다. 즉, 순차적인 의사결정 단계를 포함하며, 현재 상태에서 다음 상태로의 전이가 확정적이 아닌 확률적으로 일어난다. MDP의 구성요소로는 의사결정 단계의 집합인 Time space, 확률과정이 취하는 값들의 집합인 State space, 특정 상태에서 취할 수 있는 행돌의 집합인 Action space, 매 단계마다 특정 상태에서 특정 행동을 취했을 때 다음 상태가 될 확률을 나타내는 trainsition probability, 그리고 이때 발생하는 reward와 감가율 $\gamma$가 있었다.
1. MDP 가치함수
MDP는 순차적으로 매 단계마다 의사결정을 내린다(sequential decision making). 의사결정을 내린다는 의미는 특정 상태 $s$에서 가능한 행동이 $a_1$과 $a_2$가 존재할 때, 어떤 action을 선택하는 게 좋을지 판단하는 것이다. 이때, 좋은 행동을 선택하기 위한 판단 근거가 필요하다. 앞서 정의한 MDP의 구성요소 관점에서 살펴보면, 현재만을 고려했을 때 보상(reward)이라는 정보를 통해 판단을 할 수 있을 것이다.
그런데, MDP는 지금 상태에서 내린 의사결정이 이후의 프로세스에도 영향을 미친다. 즉, 현재 단계에서 어떤 action을 선택하면 좋을지 판단하기 위해서는 이후의 미치는 영향까지 모두 반영한 지표를 사용해야 한다. 이러한 개념을 반영하고 있는 것이 가치함수(value function)다. 그리고 MDP의 가치함수는 상태-가치 함수와 행동-가치 함수 두 가지가 있다.
1.1 상태-가치 함수(State-value function) $v$
상태-가치 함수는 의사결정시점 $t$에서의 상태가 $s$일 때, $t$시점부터 정책 $\pi$를 따르는 경우 기대되는 누적 보상합이다. 다시 한 번 정책의 의미를 살펴보면, 매 의사결정 시점마다 모든 상태에 대해서 어떤 행동을 취해야할지 알려주는 일종의 함수 또는 확률분포들의 집합을 의미한다. 즉, 내가 어떤 상황에서 어떤 행동을 취해야할지 주어진 상황에서 상태-가치 함수가 정의된다.
벨만 기대 방정식(Bellman Expectation Equation)
$$v_t^\pi(s) = E^{\pi}[G_t | S_t = s] \\= E^{\pi}[\underset{k=0}{\sum}{\gamma^k R_{t+k}|S_t=s}] = E^{\pi}[R_t + \gamma v_{t+1}^\pi(s_{t+1})|S_t=s]$$
위 식의 마지막 부분을 보면, 상태-가치 함수 $v_t(s)$는 지금 단계에서 얻어지는 보상 $R_t$와 그 이후에 얻어지는 보상들의 누적합 $v_{t+1}(s_{t+1})$의 재귀식으로 표현할 수 있다. 여기서 $R_t$는 $r_t(s,\delta_t(s))$ 즉, 주어진 정책 $\pi$를 따라 의사결정을 내려 얻은 보상이다.
이해를 위해 아래 그림의 예시를 보자. $\pi_1$과 $\pi_2$ 두 가지의 정책이 있다고 가정해보자. 현재 상태 $S$에서 정책 $\pi_1$을 따르면 크게 3가지 에피소드가 발생하고, 각각의 에피소드가 동일한 확률로 발생한다고 가정하자. $\pi_2$도 비슷하게 가정하면, $v_t^{\pi_1}(s)$와 $v_t^{\pi_2}(s)$는 각각 아래와 같이 계산할 수 있다.

1.2 행동-가치 함수(Action-value function) $Q$
행동-가치 함수는 의사결정시점 $t$에서의 상태가 $s$일 때, 행동 $a$를 취한 후 다음 시점 $t+1$ 이후부터 정책 $\pi$를 따른 경우 기대 누적 보상합이다. 다시 말해, 지금 단계에서 행동 $a$를 취하고, 그 다음 단계부터 프로세스가 종료될 때까지는 주어진 $\pi$ 정책에 때라 의사결정을 했을 때 기대할 수 있는 누적 보상합을 의미한다. 상태-가치 함수가 지금으로부터 기대되는 누적 보상합이라면, 행동-가치 함수는 지금 행동으로부터 기대되는 누적 보상합이라고 볼 수 있다.
$$Q_t^\pi(s,a) = E^\pi[G_t|S_t=s, A_t=a] = E^{\pi}[\sum_{k=0}{\gamma^{k}R_{t+k}| S_t=s, A_t=a}]\\
=E^\pi[R_t + \gamma Q_{t+1}^\pi(s_{t+1}, \delta_{t+1}(s_{t+1}) | S_t=s, A_t=a]$$
위 식을 살펴보면, 현재 상태 $s$에 있을 때, 취할 수 있는 여러 행동 $a$들 중 어느 행동을 취하는 것이 좋을지를 판단할 수 있다. 마지막 부분을 살펴보면, 행동-가치 함수 $Q_t(s)$는 지금 단계에서 얻어지는 보상 $R_t$와 그 이후에 얻어지는 보상들의 누적합 $v_{t+1}(s_{t+1})$의 재귀식으로 표현할 수 있다. 여기서 $R_t$는 $r_t(s,a)$ 즉, 주어진 정책 $\pi$를 따는 것이 아니라, $a$라는 특정 action을 취했을 때 얻는 보상이다.

상태-가치 함수에서의 $R_t$는 현재 시점 $s$에서 정책 $\pi$에 의해서 의사결정을 했을 때 얻어지는 보상이라는 의미이지만, 행동-가치 함수에서 노란색으로 표시한 보상 $R_t$는 현재 상태 $s$에서 $a$라는 행동을 했을 때 얻어진 보상이라는 차이점이 있다. 그 이후의 $R_{t+1}$부터는 정책 $\pi$에 의해서 의사결정을 했을 때 얻어지는 보상이 된다.
이해를 위해 아래 그림의 예시를 보자. 현재 상태 $S$에서 선택할 수 있는 행동은 왼쪽과 오른쪽 두 가지가 있다고 가정하자. 그 다음 단계부터는 정책 $\pi$를 따르게 된다. 이때 각 행동에 대한 행동 가치 함수를 계산해보면 오른쪽은 100, 왼쪽은 20이었다고 하자. 그러면 상태 $S$에서는 그 이후 정책이 주어졌을 때, 오른쪽을 선택하는 것이 더 좋다고 판단할 수 있다. 즉, 행동-가치 함수를 통해 현재 상태에서 정책이 주어졌을 때, 가능한 행동의 가치를 비교해볼 수 있다.
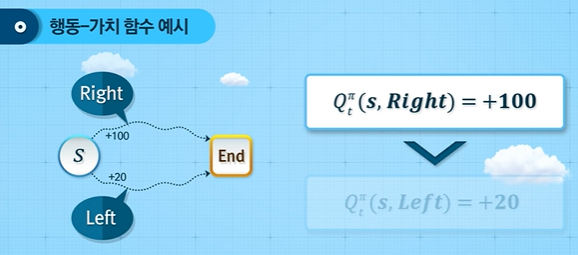
1.3 상태 가치함수와 행동 가치함수의 관계
행동 가치함수는 현재 단계에서만 $a$라는 행동을 취하고, 그 이후에는 정책 $\pi$를 따르는 것이다. 반면, 상태 가치함수는 현재 단계부터 정책 $\pi$를 따르는 것이기 때문에 두 가치함수 간 관계는 다음과 같다. 첫 번째 방정식은 정책이 확정적일 때의 관계이며, 두 번째 방정식은 정책이 확률적으로 주어졌을 때의 경우다.

즉, 확정적일 때는 지금 시점의 행동도 정책을 따르는 것이다. 확률적일 때는 현재 상태에서 가능한 행동 가치함수들의 기대값과 같다. 즉, 행동 가치함수의 모든 행동들에 대한 평균을 취한 것이 상태 가치함수라는 것이다. 상태 $S$로부터 기대되는 보상은 현재 상태에서 취할 수 있는 모든 행동들에 대한 보상의 평균이라는 이야긴데, 직관적으로 와닿는다. 아래 예시를 살펴보자.

위 그림에서 0.2, 0.3, 0.5는 정책 $\delta_t(a|s)$ 값들이고, 10, 5, 8은 행동 가치함수 즉, $Q_t(s,a)$를 나타낸다. 그럼 여기서 상태 가치함수 $v_t^\pi(s)$는 각 행동 가치함수와 그들을 선택할 확률 간의 곱 즉, 기대값으로 정의할 수 있다.
1.4 행동 가치함수와 상태 가치함수의 관계

행동 가치함수와 상태 가치함수와의 관계 역시 위와 같이 정리할 수 있다. 이를 이해하기 위해 아래 그림을 살펴보자.
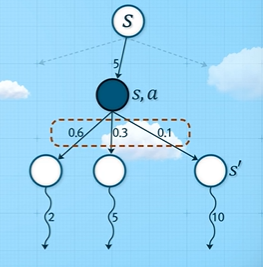
위 그림은 현재 $S=s$라는 상태에 있을 때, $a$라는 action을 취하게 된 상황을 나타내고 있다. 이때의 보상은 5이며, $s$와 $a$가 주어졌을 때, 상태 전이 확률에 의해 다음 상태 값이 결정되는 찬스 노드(chance node)에 도달하게 된다. 이때 전이확률은 각각 0.6, 0.3, 0.1로 시스템에 의해 주어져있다. 그 아래로 구불거리는 화살표 옆 숫자 2, 5, 10은 각각 다음 상태 $s^\prime$에서의 상태가치인 $v_{t+1}^\pi (s^\prime)$ 값들을 나타낸다.
위와 같은 상황이 주어졌을때, $t$시점에서 $a$라는 행동의 가치를 나타내는 행동가치함수 $Q_{t}(s,a)$는 $R_t + \sum_{s^\prime \in S}{p(s^\prime|s,a) \cdot v_{t+1}(s^\prime)}$ 즉, $5 + \gamma (0.6 \cdot 2 + 0.3 \cdot 5 + 0.1 \cdot 10)$로 계산할 수 있다. 이 식은 상태 $s$에서 행동 $a$를 취한다면, 즉시 얻어지는 보상 5와 그 이후에는 0.6의 확률로 2라는 누적보상합을, 0.3의 확률로 5의 누적보상합을, 그리고 0.1의 확률로 10이라는 누적보상합을 받을 수 있다고 이해할 수 있다.
참고로, 상태 가치함수, 행동 가치함수 그리고 이 둘의 관계는 아래와 같이 증명할 수 있다.



1.5 최적 정책과 최적 가치함수
다시 한 번 우리의 목표를 상기해보자. 우리의 관심은 누적 보상합을 최대화할 수 있는 정책을 찾는 것이다. 우선 누적 보상합을 최대화하는 정책에 대해 정의를 해보자. 시간 공간이 유한한 finite-horizon의 경우, 만약 최적 정책(optimal policy)이 존재한다면, 다음과 같이 정의할 수 있다.

모든 상태 $s$에 대해 어떤 정책 $\pi^*$가 존재할 때, 항상 임의의 다른 정책 $\pi$보다 첫 번째 단계에서부터 마지막 단계까지의 누적 보상합의 기대치가 항상 크거나 같은 경우가 성립한다면 이러한 $\pi^*$를 최적 정책이라고 한다.
또한, 이때의 가치함수를 최적 가치함수(optimal value function)라고 한다. 모든 상태에 대해서 $v_1^{\pi}(s)$ 즉, 첫 번째 시점에서 $s$라는 상태가 주어졌을 때, 모든 $\pi$에 대해 얻을 수 있는 상태 가치함수 중 최대값을 갖는 가치함수를 최적 가치함수라고 한다. 다시 말해, 만약 $\pi^*$라는 정책이 최적정책이라면, 모든 $s$에 대해서 최적 가치함수를 갖는다.

1.6 벨만 최적 방정식(Bellman optimality equation)
그러면 어떻게 최적 가치함수를 구할 수 있을까? 현실적으로 가능한 정책이 무수히 많기 때문에 모든 정책을 평가한다는 것은 불가능에 가깝다. 따라서, 이를 효과적으로 찾는 재귀 방정식이 있는데 이를 벨만 최적 방정식이라고 한다.

앞서 가치 함수는 다음과 같이 나타낼 수 있었다.
$$v_t(s) = E[r_t(s,a) + \gamma v_{t+1}(s) | S_t = s]$$
여기서 상태 $s$는 시스템으로부터 주어지는 내가 결정할 수 없는 값이며, 내가 선택할 수 있는 건 행동 $a$뿐이다. 따라서, 상태 $s$가 주어졌을 때, 가능한 행동들 중 즉시 얻는 보상과 그 이후 받을 수 있는 누적보상합의 기대값이 최대가 되는 행동을 선택했을 때의 가치함수 최적 가치함수 값이라고 볼 수 있다.
위 식에서 기대값 부분 $E[v_{t+1}^* (s)]$를 풀어쓰면 다음과 같다.

즉, 현재 상태 $s$에서 행동 $a$를 취함으로써 가능한 모든 상태들에 대해 각 상태의 상태가치함수 값의 평균이다. 즉, 위 식을 다시 한번 풀어보면, $t$시점에 $s_t$라는 상태에 있을 때 $a_t$라는 행동을 취했을 때 얻을 수 있는 누적 보상합의 최대값을 의미한다.
아래 예를 보자. 현재 $t$시점에 상태 $s$에 있을 때, 행동 $a_1$, $a_2$가 있다. 행동 $a_1$을 취한다면 $r_t(s,a_1) + \gamma(p_t(s^\prime | s, a_1)\cdot v_{t+1}^*(s^\prime) + p_t(s^{\prime \prime \prime} | s, a_1)\cdot v_{t+1}^*(s^{\prime \prime \prime}))$가 되고 같은 방법으로 행동 $a_2$에 대해서도 구할 수 있다. 그리고 이 둘 중 더 큰 값이 현재 상태 $s$에서 누적 보상합의 최대값, 즉 최적 가치함수 값이 된다.

1.7 Finite-horizon MDP의 해법
그럼 최적 가치함수 $v_t^*{s}$를 구하기 위해서는 어떻게 해야할까? 바로 동적계획법에서 배웠다시피 역진귀납법을 이용하면 된다. 여기서 $r_N^*(s)$는 finite-horizon의 경우 마지막 상태 $N$에 대한 terminal reward를 의미한다. 이를 시작으로 역순으로 $t=1$까지 구해나가면 된다.

이렇게 최적 가치함수 값을 구하면서 함께 최적 가치함수값을 만드는 행동들의 모음이 바로 최적 정책이 된다.
2. Infinite-horizon MDP
앞선 내용들은 시간 공간이 유한한 finite-horizon MDP에 대한 내용이 주를 이뤘다. 이번에는 시간 공간이 무한한 즉, MDP가 무한히 지속되는 infinite-horizon MDP에 대해서 살펴보자. Infinite-horizon MDP는 강화학습에서 가장 중요한 파트 중 하나이다. 추후 살펴보겠지만, Infinite-horizon MDP 모델을 푸는 것을 모델 기반 강화학습(model-based reinforcement learning)이라고 한다.

Infinite-horizon MDP는 프로세스가 무한히 지속되기 때문에, 수학적인 단순성을 위해 정상성(stationary) 가정을 한다. 지금까지 살펴본 내용에서는 보상 $r_t(s,a)$에서 $t$는 동일한 상태에서 동일한 행동을 취했을 때도 단계별로 보상이 달라질 수 있음을, 상태전이행렬 $p_t(s^\prime | s, a)$ 역시 동일한 상태에서 동일한 행동을 취했을 때 단계에 따라 다음 상태 $s^\prime$이 될 확률이 달라질 수 있음을 내포하고 있다. 따라서, 정상성 가정을 통해 보상과 상태전이행렬이 의사결정시점(단계) $t$에 의존하지 않는다고 가정한다.
정상성 가정
- 보상과 상태전이행렬이 의사결정시점(단계) $t$에 의존하지 않는다고 가정
$$r_t(s,a) → r(s,a) \\ p_t(s^\prime|s,a) → p(s^\prime|s,a)$$
지금까지 살펴본 정책은 모든 시점에서의 의사결정 규칙을 모아놓은 것이었다. 즉, 의사결정 규칙이 시점에 따라서 달라지기 때문에 동일한 상태 $s$에 있어도 시점에 따라 행동이 달라질 수 있는 것이다.

그러나, Infinite-horizon MDP에서 보상과 상태전이확률이 정상성 가정을 만족한다면 최적의 정상 정책(optimal stationary policy)가 존재한다고 알려져있다. 이때 최적의 정상 정책이란, 모든 단계에서 동일한 의사결정 규칙 $\delta$가 적용되는 정책을 의미한다.

2.1 Infinite-horizon MDP의 상태가치함수

Infinite-horizon 모델의 경우, 감가율 $\gamma$가 중요한 의미를 가진다. 왜냐하면 단계가 무한하기 때문에 감가율이 존재하지 않는다면, 누적보상합이 무한대로 발산할 수 있기 때문이다. 따라서 감가율의 의미를 살펴보면 다음과 같다.
- 감가율(discouint factor) $\gamma$
- $\gamma = 0$: 오직 현재 시점의 보상만을 중요시 함
- $\gamma \approx 1$: 먼 미래의 보상을 현재와 가까운 미래의 보상만큼 중요시 함
- 벨만 기대 방정식(Bellman Expectation Equation)
현재 상태에서의 가치함수와 다음 상태에서 가치함수 간의 관계를 나타내는 벨만 기대 방정식 역시 존재하는데, 정상성 가정을 통해 도출이 훨씬 간결해졌다. 정책 $\pi$가 주어졌을 때, 상태 $s$의 가치함수는 정책 $\pi$를 따라 행동했을 때 얻는 즉각적인 보상 $r(s,\pi(s))$과 상태전이에 의한 다음 상태 $s^\prime$에서 얻을 수 있는 상태 가치함수들의 기대값$\sum_{s^\prime}{[p(s^\prime|s,\pi(s)) \cdot v^\pi(s^\prime))]}$으로 이루어진다.

만약 정책 $\pi$가 확률적인 경우에는 다음과 같이 상태 $s$가 주어졌을 때 행동에 대한 확률을 곱해주어 기대값 형식으로 구하게 된다.

2.2 정책 평가(Policy evaluation)
벨만 기대 방정식을 통해 모든 상태에서의 상태 가치함수 값을 계산할 수 있다. 이처럼 Infinite-horizon MDP에서 정책이 주어졌을 때, 정책에 따른 모든 상태에 대한 가치함수 값을 산출해내는 과정을 정책 평가라고 한다.
예시로 $s_1, s_2, s_3$ 3개의 상태가 있는 Infinite-horizon MDP 모델을 생각해보자. 또한, 정상 정책 $\pi$도 주어져 있다고 가정해보자. 그러면, 벨만 기대 방정식을 다음과 같이 martrix form으로 나타낼 수 있다.
$$v^\pi (s) = r(s, \pi(s)) + \gamma \sum_{s^\prime}{p(s^\prime|s,\pi(s)) v^\pi(s^\prime)}$$
$$ \begin{pmatrix} v^\pi (s_1) \\ v^\pi (s_2) \\ v^\pi (s_3)\end{pmatrix} = \begin{pmatrix} \gamma(s_1, \delta(s_1)) \\ \gamma(s_2, \delta(s_2)) \\ \gamma(s_3, \delta(s_3))\end{pmatrix} + \gamma \begin{pmatrix} p(s_1|s_1, \delta) & p(s_2|s_1, \delta) & p(s_3|s_1, \delta) \\ p(s_1|s_2, \delta) & p(s_2|s_2, \delta) & p(s_3|s_2, \delta) \\ p(s_1|s_3, \delta) & p(s_2|s_3, \delta) & p(s_3|s_3, \delta) \end{pmatrix} \begin{pmatrix} v^\pi(s_1) \\ v^\pi(s_2) \\ v^\pi(s_3) \end{pmatrix}$$

위 식은 Markov Reward Process에서 각 상태의 가치 계산 과정과 동일하다. 왜냐하면, MDP에서 모든 상태에 대해 정책이 주어져 있다면, 즉, 행동이 결정되어 있다면 MRP와 동일하게 되기 때문이다. 또한, 좌변과 우변의 $V^\pi$는 동일함을 알 수 있는데, 이는 프로세스가 무한 진행되며 정상성 가정에 따라 시점에 따른 영향을 받지 않기 때문이다.
2.3 최적 가치함수(Optimal value function) $v^* (s)$와 최적 정책 $\pi^*$
Inifinite-horizion MDP에서도 최적 가치함수에 대해 정의할 수 있다. 즉, 모든 상태 $s$에 대해 모든 가능한 정책 $\pi$으로 계산한 상태 가치함수 중 최대값을 갖는 가치함수를 최적 가치함수라고 한다.

최적 정책은 모든 상태에 대해서 최적 가치 함수 값을 도출해내는 것을 의미한다.

2.4 벨만 최적 방정식(Bellman optimality equation)
MDP 모델을 통해 최종적으로 구하고자 하는 것은 최적의 정책이라는 의사결정의 규칙이다. 이때 Inifite-horizon의 경우, 앞서 살펴본 finite-horizon MDP의 벨만 최적 방정식에서 시점 $t$가 제거된 형태와 같다. 여기서 $v^*(s)$는 $s$라는 상태로부터 무한히 프로세스가 진행되었을 때 얻을 수 있는 감가율이 고려된 누적보상합의 기대값의 최대값을 의미한다.

또한, 주의해서 볼 부분은 좌변의 $v^*(s)$와 우변의 $v^*(s^\prime)$에서 최적 가치함수 $v^*$는 동일한 최적 가치함수다. 시간 공간이 무한하기 때문에 현재 시점의 $s$에서부터 무한대의 미래로 가는 것이나 미래의 $s$로부터 무한대의 미래로 가는 것이나 얻는 누적보상합의 최대값이 같다고 볼 수 있다. 즉, 누적보상합의 최대값이 시점에 따라 변하지 않는다. 따라서, 좌변의 $v^*$와 우변의 $v^*$는 같은 가치함수라고 이해하자.
만약 벨만 최적 방정식을 만족하는 최적 가치 함수 $v^*$를 얻었다고 가정해보자(벨만 최적 방정식을 구하는 방법은 추후 다룬다). 그럼 궁극적으로 관심있는 모든 최적 정책은 어떻게 구할 수 있을까? $v^*$를 계산했기 때문에 모든 상태에 대해, 모든 $a$에 대해 아래 식을 모두 계산해본다.

그 후 모든 $s$에 대해 $a$를 mapping하면 의사결정 규칙이 된다. 또한, 모든 단계에서 모두 동일하게 적용되기 때문에 이런 의사결정 규칙의 모음이 최적 정책이 된다.
2.5 최적 행동 가치함수 $Q^*(s,a)$
최적 행동 가치함수는 상태 $s$에서 행동 $a$를 결정한 이후, 최정정책을 따를 때 얻을 수 있는 기대값을 의미한다. 이를 통해 현재 상태 $s$에 있을 때, 어느 행동을 취해야 내가 가장 좋은 누적보상합의 최대값을 얻을 수 있는지 판단할 수 있다.

위 식의 $r(s,a)$는 행동 $a$에 대한 즉각적인 보상, $p(s^\prime | s.a)$에 의해 다음 상태 $s^\prime$으로 전이, $v^*(s^\prime)$은 전이된 상태로부터 내가 얻을 수 있는 누정보상합의 최대값이다. 즉, 이를 통해 $Q^*$와 $v^*$간의 관계식이 도출되었다.
그런데, 위 식은 앞서 살펴본 벨만 최적 방정식에 포함되어 있다. 결국 $v^*(s)$는 행동 $a$값에 대한 $Q^*(s,a)$의 최대값이다. 그리고 최적정책은 모든 $s$에 대해서 $Q^*(s,a)$를 maximize하는 $a$들을 모아둔 것이다.

'Reinforcement Learning > 강화학습의 수학적 기초와 알고리듬 이해' 카테고리의 다른 글
| Week9. 강화학습 알고리즘-1 (0) | 2022.04.06 |
|---|---|
| Week7. MDP-3 (0) | 2022.04.06 |
| Week5. MDP-1 (0) | 2022.04.01 |
| Week4. 마르코프 과정 (0) | 2022.03.31 |
| Week3. 동적계획법2 (0) | 2022.03.29 |



