
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- adaptive_rag
- fastapi
- rag
- 추천시스템
- Python
- tool_call_chunks
- 강화학습
- agenticrag
- tool_calls
- update_state
- rl
- toolnode
- chat_history
- REACT
- RecSys
- LangChain
- pinecone
- summarize_chat_history
- Docker
- conditional_edges
- 밑바닥부터 시작하는 딥러닝
- langgraph
- 강화학습의 수학적 기초와 알고리듬의 이해
- 강화학습의 수학적 기초와 알고리듬 이해
- subgraph
- 밑바닥부터시작하는딥러닝 #딥러닝 #머신러닝 #신경망
- langgrpah
- removemessage
- add_subgraph
- Ai
- Today
- Total
타임트리
Week4. 마르코프 과정 본문
마르코프 의사결정 프로세스(Markov decision process; MDP) 강화학습의 수학적 근간이 되는 이론적인 배경이다. 하지만 곧바로 MDP는 확률적 동적 계획법과 마르코프 프로세스가 합쳐진 것이므로 MDP를 배우기에 앞서, 마르코프 과정(Markov procss)에 대해 먼저 알아보자.
1. 불확실성 모델링
- 확률(Probability)
- 주위에서 발생하는 여러 사건들은 근본적으로 불확실성을 내포
- 불확실성을 표현하는 수단
- 불확실성을 확률변수와 확률분포를 사용해 수학적으로 모델링
- 확률변수와 확률분포
- 예시) 날씨는 맑음, 흐림, 비로 구성되어 있다고 하자. 날씨라는 불확실성을 내포한 시스템을 모델링하기 위해 날씨의 상태라는 확률변수를 정의하면, 다양한 분석을 가능하게 한다.
- $X=1$ (맑음), $2$ (흐림), $3$ (비)
- $P(X=1)=0.6$, $P(X=2)=0.2$, $P(X=3)=0.2$
- 시간에 따른 날씨의 시계열
- 시간에 흐름에 따라 불확실성이 변동(불확실성 + 오늘 날씨와 내일 날씨의 연관성 존재)
- 맑음 → 흐림 → 흐림 → 비, 맑음 → 맑음 → 흐림 → 비, ...
- 예시) 날씨는 맑음, 흐림, 비로 구성되어 있다고 하자. 날씨라는 불확실성을 내포한 시스템을 모델링하기 위해 날씨의 상태라는 확률변수를 정의하면, 다양한 분석을 가능하게 한다.
2. 확률 과정(Stochastic process)
확률 과정이란 시간에 따라 어떤 사건이 발생할 확률값이 변화하는 일련의 과정을 의미한다. 앞서 불확실성을 지닌 시스템을 모델링 하기 위해 확률변수와 확률분포를 사용한다고 언급했듯, 확률 과정 역시 각각의 어떤 시점을 하나의 확률변수로 둔다. 즉, 시간에 따른 확률변수들의 집합을 통해 불확실성을 모델링한다. 이를 위해 몇 개의 개념을 살펴보자.
- 확률변수들의 집합: $\{X_t: t \in T\}$
- 시간 공간 (Time space) $T$: 관찰 시점들의 집합
- 상태 공간 (State space) $S$: 확률과정을 따르는 확률변수 $X_t$가 가질 수 있는 모든 가능한 값의 집합
즉, 확률 과정은 시간공간 $T$와 상태공간 $S$에서 정의된 확률변수들의 집합을 말하며, 이때 확률변수는 상태 공간 내의 값을 시간 공간에 속하는 관찰 시점마다 갖게 된다.
확률 과정 예시 - 동전 던지기
- 게임 개요
- 동전을 하나 던져서 앞면이면 +1점, 뒷면이면 -1점을 얻는 동전 던지기 게임
- 플레이어가 종료를 선언한 시점에서 게임이 종료되며, 점수는 0점부터 시작
이를 확률과정이라는 개념을 통해 설명해보면 다음과 같다.
- 시간 공간 $T = \{0, 1, 2, ...\}$
- 상태 공간 $S = \{s: s \in (-\infty, \infty)\}$
- 확률 변수 $X_t$: $t$번째 동전을 던졌을 때의 누적 점수

이처럼 동전 던지기 예시는 시간의 흐름에 따라 불확실성을 가지고 변동되는 프로세스로 확률 과정의 예라고 볼 수 있다.
확률 과정의 4가지 분류
확률 과정은 다음과 같이 시간 공간과 상태 공간이 이산형(discrete)인지 연속형(continuous)인지에 따라 다음과 같이 4가지로 분류해볼 수 있다.
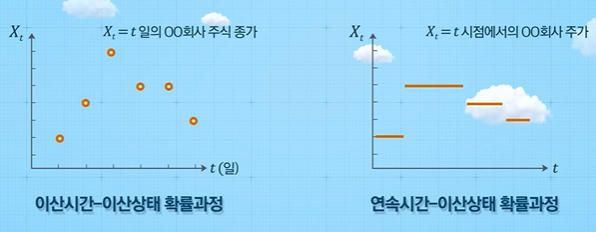
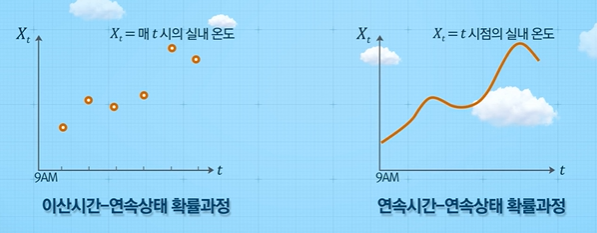
이 수업에서는 주로 첫 번째에 위치한 이산시간 - 이산상태 확률과정에 초점을 맞춘다.
확률 과정과 관련된 몇 가지 정의
- 샘플 경로; 에피소드 (Sample path; episode)
- 시간 $t$가 변함에 따라 확률 과정 $\{X_t: t \in T\}$이 갖는 값의 자취
- 확률 과정의 실현 값들을 모아 놓은 것 (일종의 시계열 데이터 샘플)
- 확률 과정이 반복될 때마다 다른 에피소드를 갖는다.
- 정상과정 (Stationary process)
- 시간 $t$에 따라 확률법칙이 변하지 않는 확률과정
- $t$에 의존하지 않는 확률 과정
예측: 확률 과정을 통해 하고자 하는 것
우리는 왜 불확실성을 내포한 시스템을 모델링할까? 이는 불확실성을 이해하고 시스템을 예측하기 위해서다. 즉, 확률 과정 $\{X_t:t \in T\}$에서 $t=k$시점까지 값이 주어졌을 때, 그 다음 시점인 $t=k+1$에서의 확률분포를 알고 싶은 것이다. 즉, 다음과 같은 조건부 확률에 관심이 있다.
$$P(X_{k+1}|X_k, X_{k-1},\cdots,X_0)$$
참고로 조건부 확률의 정의에 따라, $P(X_0, X_1, \cdots, X_k) = P(X_0)P(X_1|X_0)P(X_2|X_1,X_0) \cdots P(X_k|X_{k-1},\cdots,X_1,X_0)$이다. 이처럼 조건부 확률을 알게 된다면, 현재 시점의 값에 따른 다음 단계의 평균을 나타내는 조건부 기대값($E[X_t+1|X_t]$) 등을 계산할 수 있다.
3. 마르코프 성질
확률과정을 따르는 확률 변수에 있어, 가장 간단한 형태의 조건부 확률은 다음과 같다(독립인 경우는 확률 과정이 필요 없으므로 제외한다).
$$P(X_{k+1}|X_k, X_{k-1}, \cdots, X_0) = P(X_{k+1}|X_k)$$
즉, 현재($k$)만이 미래($k+1$)를 결정하는 지표인 경우이다. 이와 같은 성질을 마르코프 성질(Markov property)이라고 하며, 마르코프 성질을 가진 확률 과정을 마르코프 프로세스(Markov process; MP)라고 한다.
4. 이산시간 마르코프 체인(DTMC)
MP 중 시간 공간이 이산형이고 상태공간 역시 이산형인 경우 이를 이산시간 마르코프 체인(Discrete-time Markov chain; DTMC)이라고 한다. 즉, DTMC는 다음의 성질을 만족하는 확률 과정 $\{X_n: n \ge 1 \}$이다.
- 모든 $n$에 대해 $X_n \in S$
- 모든 $i,j \in S$에 대해,
$$P(X_{n+1} = j|X_n=i, X_{n-1}, \cdots, X_1) = P(X_{n+1}=j|X_n =i)$$
2번 성질은 마르코프 성질을 의미한다. 우변의 $P(X_{n+1}=j|X_n =i)$는 상태가 한 단계에서 다음 단계에서 어떻게 변환이 될지를 기술한 확률로 볼 수 있기 때문에 이를 상태 전이확률(1-step transition probability)이라고 한다. 즉, 상태 전이확률은 $i$상태에서 $j$가 될 확률을 의미한다.
"상태"전이 확률은 말 그대로 상태에 대한 전이를 기술한 확률이므로, 단계 $n$별로 정의가 가능하다. 즉, 시점 1에서 상태 $i$가 시점 2에서 상태 $j$가 될 확률과 시점 100에서 상태 $i$가 시점 101에서 상태 $j$가 될 확률은 다를 수 있다.
시간 동질(time-homogeneous) DTMC
분석의 용이를 위해 상태 전이확률이 시점 $n$과는 독립적인 상황을 생각해보자. 이와 같은 경우를 시간 동질 이산시간 마르코프 체인(time-homogeneous DTMC)이라고 한다.
- 전이확률 $P(X_{n+1}=i|X_n=j)$이 $n$에 독립
- $P(X_{2}=i|X_1=j) = P(X_{3}=i|X_2=j) = \cdots = P(X_{n+1}=i|X_n=j)$
즉, $P(X_{n+1}=i | X_n=j) = p_{ij}$
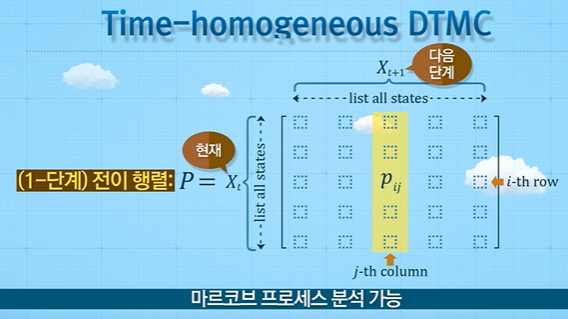
time-homogeneous라면, 다음과 같은 전이 행렬을 만들 수 있다. 전이 행렬이란, 내가 현재 $i$라는 상태에 있을 때, 다음 상태가 $j$가 될 확률들을 모든 상태에 대해서 행렬로 표현한 것이다. 사실, 전이 행렬만 있다면 마르코프 프로세스를 분석할 수 있으며, 이후 보겠지만, 전이 행렬을 작성할 수 있다면, 마르코프 성질을 만족한다고 볼 수 있다.
5-1. 마르코프 체인 예시 1

위와 같은 미로에 쥐가 1번 방에 위치한다고 하자. 쥐는 한 칸씩 랜덤하게 이동하며, 3번 방 혹은 9번 방에 도착하면 해당 방에 머무른다. 이러한 상황에서 쥐가 시간의 흐름에 따라 이동하는 확률 과정을 모델링 해보자.
마르코프 체인 정의
- Time $N$: 쥐가 한 번 움직일 때를 한 단계로 가정
- Time space: $N = \{ 0,1,2,3,\cdots \}$
- Random variable $X_n$ := $n$번째 단계에서 쥐의 방 번호
- State space: $S = {1,2,3,4,5,6,7,8,9}
- Sample path(episode) example: (1 → 2 → 5 → 6 → 3), (1 → 4 → 5 → 6 → 9) , ...
마르코프 성질이란 다음 단계의 상태가 현재 상태에 의존적인 것을 의미한다. 따라서, 전이 확률(trainsition probability) 을 정의할 수 있다면, 이와 같은 확률 변수들의 모음인 확률 과정이 마르코프 체인이라고 말할 수 있다. 다시 말해, 전이 행렬은 가능한 모든 현 단계와 다음 단계 상태 값의 행과 열을 모두 나열한 것이므로, 전이 행렬을 작성할 수 있다면, 마르코프 성질을 만족한다고 볼 수 있다. 그럼 이 예시에서의 전이 행렬을 나타내보자.
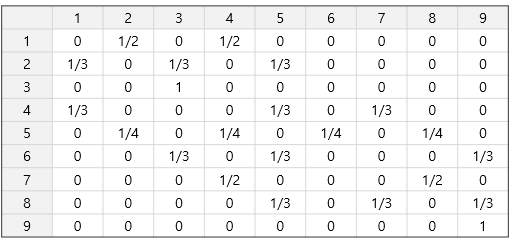
1-단계 상태 전이 행렬을 작성할 수 있으므로, 과거 이력과 상관없이 다음 상태가 결정되는 마르코프 성질을 만족하는 확률 과정이라고 할 수 있다.
5-2. 마르코프 체인 예시 2
이번에는 다음과 같은 재고 관리 상황을 생각해보자.
- 재고 관리자
- 매주 금요일 창고 재고 확인
- 물건이 부족하면 발주하여 다음주에 판매할 물건 준비
- 발주 규칙
- 재고 수준이 3 이상이면 발주하지 않음
- 재고 수준이 3 미만이면 발주 후 재고 수준이 5가 되도록 주문량 결정
- 주차별 수요에 대한 확률 분포 - 재고관리자가 수요발생확률을 알고 있음
- 금요일 발주 시 주말 중 물건이 도착하여 월요일부터 판매 시작
- 영업일은 월요일 ~ 금요일

- 물건 품절 시 주문 접수를 받지 않음
마르코프 체인 정의
- Random variable $X_n$ := $n$번째 주 금요일 영업 종료 후 재고 수준
- Time $n$: 주차
- Time space $N = \{1,2,3,\cdots\}$
- State space: $S = {0,1,2,3,4,5}
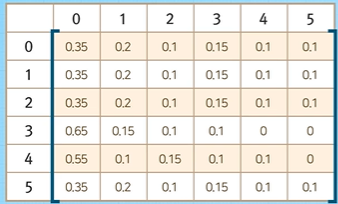
상태 전이 행렬의 (1,1)이 어떻게 계산되는지 살펴보자. 만약 현재 시점에 재고가 없다면($X_n = 0$), 물건 5개를 발주할 것이고 다음주 월요일 재고는 5가 될 것이다. 이때, 주차별 수요의 확률분포에 따라 다음주 재고가 0($X_{n+1}=0$)이려면 수요가 5개 또는 6개 발생해야 한다. 따라서, 이의 확률은 $P(D=5) + P(D=6) = 0.35$가 된다.
5-3. 마르코프 체인 예시 3
확률 과정 $\{X_n\}$에 대해, $P(X_{k+1}|X_k, X_{k-1}, \cdots, X_0) = P(X_{k+1}|X_k,X_{k-1})$인 상황을 생각해보자. 이는 마르코프 성질을 만족한다고 할 수 없다. 왜냐하면 상태가 현재($k$)뿐만 아니라, 과거($k-1$)에도 의존적이기 때문이다. 하지만, 다른 형태로 확률 과정을 정의한다면 마르코프 성질을 만족하는 마르코프 프로세스로 변환할 수 있다. 다음과 같이 확률변수를 2개씩 묶어보자.
$$\{(X_k,X_{k+1})|(X_0, X_1), (X_1,X_2), (X_2, X_3), \cdots\}$$
이러한 형태의 확률 과정이 마르코프 프로세스인지를 살펴보기 위해서는 상태 전이 확률을 계산할 수 있는지를 살펴보면 된다. 즉, 다음 식이 만족하는데, 이는 첫 부분 식에서의 우변과 같다. 따라서, 두 개씩 묶은 확률 과정은 마르코프 과정이라고 볼 수 있다.
$$P((X_k, X_{k+1}) | (X_{k-1}, X_k)) = P(X_{k+1} | X_{k-1}, X_k)$$
대표적인 벽돌깨기 게임 Atari에 적용된 강화학습 모델에서도 스냅샷 하나로 공의 이동정보를 알 수 없기 때문에 다음과 같이 과거 4장의 이미지를 하나로 묶어 input값으로 넣어 상태를 정의했다.
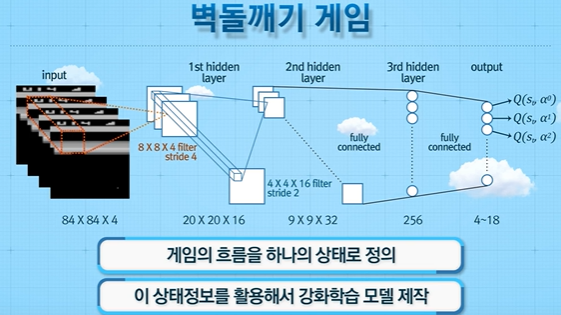
마찬가지로, 만약에 과거 3개의 의존적인 조건부 확률이 주어져있는 확률 과정은 3개씩 묶어주고 상태전이를 관찰한다면 해당되는 프로세슨느 마르코프 성질을 만족하게 된다. 하지만, 이러한 방법은 상태공간의 크기가 매우 커진다는 문제점이 있다. 이러한 문제점을 인지하고 있어야 한다.

6. 마르코프 보상 프로세스 (Markov reward process)
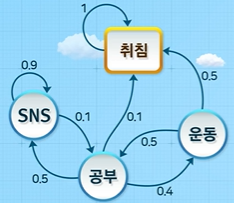
마르코프 체인(상태가 discrete)에 따라 확률적으로 움직이는 학생이 있다고 가정해보자. 즉, 현재 상태가 다음 상태를 결정하며, 과거는 영향을 미치지 않는다. 아래 그림은 상태 전이 다이어그램(state transition diagram)으로, 마르코프 체인은 현재와 다음 상태 간 관계만 있으면 되므로 이처럼 표현 가능하다. 각 상태는 노드, 화살표는 전이 방향, 화살표 옆 숫자는 전이 확률을 이야기 한다.
위 다이어그램을 익숙한 상태 전이 행렬로 나타내면 다음과 같다.
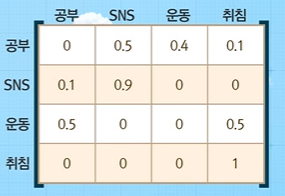
이처럼 MP가 있는 상황에서 보상이라는 개념이 도입된 것이 마르코프 보상 프로세스(MRP)가 된다.
마르코프 보상 프로세스(MRP)
- 보상 개념 도입
- 특정 상태에 제공하는 인센티브
- 액션을 취할 때 보상이 주어지는 것이 아닌, 행동은 확률적으로 확률에 의해 정해짐
- 구성 요소
- $S$=상태집합
- $P$=상태전이확률 ($P[S_{t+1}=s^`|S_t=s]$)
- $R$=보상(reward) 함수 ($R_s = E[R_t|S_t=s]$)
- $\gamma$=감가율(discounting factor): 시간의 흐름에 따라 보상의 가치 변화를 반영
- 에피소드(episode)
- 특정 상태로부터 시작하여 종료 상태까지의 상태 혹은 보상의 sequence
- 현재 상태 $S_t$=공부일 경우, (공부 - SNS - SNS - 공부 - 취침), (공부 - 취침), ...
- 에피소드별로 방문하는 상태가 다양하므로, 보상이 달라짐
- 리턴(Return) $G_t$: $t$번재 시점 이후의 감가율이 반영된 누적 보상합
- $G_t = R_t + \gamma R_{t+1} + \gamma^2 R_{t+2} + \cdots = \sum_{k=0}^\infty{\gamma^k R_{t+k}}$
- 현재부터 발생한 하나의 에피소드에서 방문했던 상태별로 얻은 보상의 합으로 이해
각 상태에 대한 보상이 다음과 같을 때, 현재 상태 $S_t$=공부일 때, 몇 개의 에피소드에 대한 리턴의 예시를 살펴보자.

참고로, 위 예를 통해 알 수 있는 정보는 다음과 같다.
- 모든 에피소드를 나열한 것이 아니다.
- 한 에피소드는 다른 에피소드의 부분일 수 있다. (eg) 공부 - 운동 - 취침)
- 각 에피소드의 확률 계산이 가능하다. ( (공부 - 운동 - 취침)의 확률: 0.4 * 0.5 = 0.2 )
그렇다면, 어떤 상태가 더 좋고 나쁜지 평가할 수 있는 지표는 어떻게 설정할까? 즉, 특정 상태로부터 시작해서 마르코프 체인에 따라 다양한 에피소드를 경험하게 되는데, 해당 상태에서 시작했을 때, 종료 상태까지 얻을 수 있는 보상측면에서 얼마나 좋은지 평가하기 위한 지표가 필요하다. 이로부터 가치함수(value function)가 등장한다. 즉, 어느 상태에서 시작해야 종료 상태까지의 보상이 최대가 될까?를 평가할 수 있다.
- 가치함수(value function) $v(s)$
- 특정 상태에서의 리턴의 기댓값
- 상태 $s$로부터 시작하는 프로세스에서 기대할 수 있는 누적보상의 평균
- $v(s) = E[G_t|S_t=s]
- 모든 에피소드를 나열하고 발생확률을 계산
- 에피소드별 누적 보상합(리턴) 계산
가치함수의 계산
가치함수를 계산함에 있어서, 현실적으로는 모든 에피소드를 나열하고 계산하는 것이 불가능하다. 따라서, 가치함수를 계산할 때는 다음과 같은 재귀식을 통해서 계산한다. 간단히 이해해보자면, 현재 상태부터 기대할 수 있는 누적보상의 기댓값은 현재 상태의 보상과 가능한 다음 상태에서의 가치들의 전이확률을 반영한 가중합끼리의 합이라고 볼 수 있다.

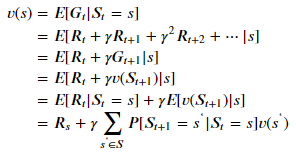
가치함수의 재귀식을 이용하여 예시에 각 상태에 대한 가치함수를 구해보자.

가치 함수를 matrix form으로 나타내면 다음과 같다.

또한, 상태 전이 행렬 $P$는 항상 역행렬이 존재한다고 알려져 있다. 따라서 $(I-\gamma P)$도 역행렬이 존재하므로, 다음과 같이 나타낼 수 있다.
$$V = R + \gamma PV$$
$$(I-\gamma)V = R$$
$$V = (I-\gamma P)^{-1} R$$
즉, 재귀식과 행렬을 이용하여 모든 상태 별로 에피소드를 다 나열할 필요 없이, 특정 상태로부터 시작하는 각 에피소드의 누적보상합의 기대치를 간단하게 계산할 수 있다.
따라서, 이번 주차를 정리하면 다음과 같다.
- 마르코프 프로세스는 확률 과정 중 마르코프 성질을 가진 확률 과정
- 마르코프 성질이란 현재가 미래를 결정한다는 것으로 현재 상태가 주어졌을 때 다음 상태가 무엇이 될 지에 대한 조건부 확률인 전이 확률을 도출해낼 수 있다면 이를 마르코프 프로세스라고 한다.
- 마르코프 프로세스에 보상 개념이 도입된 것이 마르코프 보상 프로세스
- 리턴은 가능한 모든 에피소드들의 누적 보상합
- 특정 상태의 가치는 모든 에피소드들의 누적 보상합의 기대값으로 이를 가치함수라고 한다.
'Reinforcement Learning > 강화학습의 수학적 기초와 알고리듬 이해' 카테고리의 다른 글
| Week6. MDP-2 (0) | 2022.04.03 |
|---|---|
| Week5. MDP-1 (0) | 2022.04.01 |
| Week3. 동적계획법2 (0) | 2022.03.29 |
| Week2. 동적계획법1 (0) | 2022.03.27 |
| Week1. 강화학습의 이해 (0) | 2022.03.23 |



