
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- subgraph
- adaptive_rag
- tool_calls
- rag
- fastapi
- toolnode
- 추천시스템
- summarize_chat_history
- 밑바닥부터시작하는딥러닝 #딥러닝 #머신러닝 #신경망
- Ai
- add_subgraph
- update_state
- 강화학습의 수학적 기초와 알고리듬의 이해
- langgraph
- Python
- REACT
- RecSys
- 강화학습
- agenticrag
- Docker
- removemessage
- langgrpah
- rl
- 강화학습의 수학적 기초와 알고리듬 이해
- chat_history
- 밑바닥부터 시작하는 딥러닝
- pinecone
- tool_call_chunks
- LangChain
- conditional_edges
- Today
- Total
타임트리
Week2. 동적계획법1 본문
강화학습의 기본적인 매커니즘을 이해하기 위해서는 동적 계획법(dynamic programming)이라는 문제 해결을 위한 방법론에 익숙해지는 것이 좋다. 따라서, 동적 계획법을 이해하는 데 도움이 되는 수학적 귀납법을 먼저 간단하게 살펴보고 넘어가자.
수학적 귀납법
- $p_1,~p_2,...$를 참 또는 거짓인 명제라고 하자. 이때
1) $p_1$이 참이고
2) 모든 $n\ge1$에 대해 $p_n$이 참일 때 $p_{n+1}$도 참이면,
3) $p_1,~p_2,...$는 모두 참이다.
다음의 식을 수학적 귀납법을 통해 증명해보자.
$$p_n: 1 + 2 + \cdots + n = \frac{n(n+1)}{2}$$
증명
1) $p_1 = \frac{1\cdot2}{2}=1$ (참)
2) $p_n$이 참이라고 하자. 그러면,
$$p_{n+1} = 1 + 2 + \cdots + n + (n+1) = \frac{n(n+1)}{2} + (n + 1)$$
$$= \frac{n(n+1)+2(n+1)}{2} = \frac{(n+1)(n+2)}{2}$$
따라서, $p_{n+1}$도 참이다.
3) 그러므로 수학적 귀납법에 의해 주어진 명제는 모든 $n$에 대해 참이다.
간단한 예이지만, 여기서 주목할 점은 증명과정에서 $p_{n+1} = p_n + (n+1)$이라는 재귀식(recursive equation)을 사용했다는 점이다. 즉, $p_n$의 정보를 이용해 $p_{n+1}$을 도출했다. 후에 살펴볼 동적 계획법 역시 재귀식을 통해 효율적인 알고리즘을 구현하는 것을 목적으로 한다.
도입 예시 1
- 아래와 같은 행렬에서 (1, 1) → (4, 5)까지의 최소비용 경로를 구하는 문제를 살펴보자.
- 오른쪽이나 아래로만 이동할 수 있다.
- 행렬 내 각 셀의 숫자는 해당 위치의 비용을 나타낸다.
- 경로의 비용은 방문한 칸들의 비용합으로 정의한다.

가장 단순한 방법으로는 (1, 1)에서 (4, 5)까지 가능한 모든 경로를 계산하여 비교 후, 가장 비용의 합이 작은 경로를 선택하는 것이다. 하지만, 더 복잡한 문제라면 이는 불가능해진다. 하지만 재귀식을 이용하면 보다 현명하게 해결이 가능하다. 이를 위해 $C_{ij}$는 각 셀의 비용을 나타낸다고 하고, 다음처럼 $V(i,j)$를 정의하자.
$V(i,j)$: ($i$, $j$)에서 (4, 5)까지의 모든 경로 중 최소의 비용
그러면, 어떻게 $V(i,j)$를 계산할 수 있을까? 이는 우측 하단부터 재귀식을 통해 계산하면 된다. 즉, 다음 그림에서 주황색으로 표시한 $V(3,4)$의 계산 과정을 보자.

$V(4,4)$의 계산값 11은 (3, 4)칸의 비용인 6과 우측 칸과 아래측 칸 중 더 작은 비용합을 갖는 $V(4,4)$의 합으로 계산된다. 즉, $V(i,j)$를 다음과 같은 재귀식으로 나타낼 수 있다.
$$V(i,j) = \min(C_{ij} + V(i+1, j), ~ C_{ij} + V(i, j+1))$$
이처럼 재귀식을 사용해 우측 하단부터 역방향으로 계산함으로써 최종적으로 우리가 구하고자 하는 (1, 1) → (4, 5)까지의 최소비용을 구할 수 있다. 이때의 최소비용은 24이다.
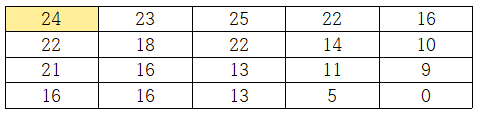
우린 주어진 재귀식으로 $V(1,1)=24$를 구했다. 그렇다면 그 경로는 어떻게 얻을 수 있을까? 이는 순차적으로 계산하는 과정에서 화살표로 기록함으로써 얻을 수 있다.
동적계획법(Dynamic programming)
- 주어진 문제를 중첩(overlapping)되는 작은 문제들로 단순화한 후 재귀적인 구조를 활용하여 전체 문제를 해결하는 방식을 말한다.
- 알고리즘 설계 전략
- 전체 문제를 일련의 중첩되는 부분문제(overlapping subproblems)로 문제 정의
- 재귀적 구조식을 정의하여 상의 부분문제와 하위 부분문제 간의 관계 도출
- 하위 부분문제를 해결한 결과를 활용해 해당 문제를 포함하는 상위 부분문제를 재귀식을 통해 해결
동적계획법은 순차적으로 의사결정을 내리는 형태의 문제를 풀고자 할 때 사용한다. 위에서 살펴본 최단 경로 문제를 생각해보자. 최단 경로 문제를 해결한 과정을 살펴보면, 전체 문제를 아래와 같이 중첩되는 하위 문제로 분할한 후, 하위 단계의 문제부터 순차적으로 해결하여 최종 문제를 해결했다.

동적계획법이 적용가능하기 위한 선행 조건
동적계획법을 사용하기 위해서 두 가지의 선행 조건이 필요하다. 만약, 특정 문제가 두 가지 선행 조건을 만족하지 않는다면 문제의 구조를 변경하여 동적계획법을 적용할 수도 있다.
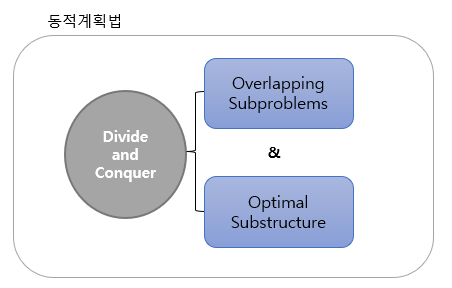
1. 중첩되는 부분문제들(overlapping subproblems)
- 부분문제나 부분문제를 포함하는 상위문제나 문제의 크기가 달라질 뿐, 문제의 형태가 동일해야 한다.
- 즉, 문제를 정의했을 때 원래 풀고자하는 문제까지도 정의가 되어야 한다.
앞서 살펴보았던 최단 경로문제에서 우리는 부분문제를 다음과 같이 정의했다.
$$V(i,j) = \min(C_{ij} + V(i+1, j), ~ C_{ij} + V(i, j+1))$$
위 식은 원래 풀고자 했던 $V(1,1)$도 포함하고 있으며, 상위 문제 $V(i,j)$와 하위 부분문제 $V(i+1,j)$, $V(i,j+1)$가 서로 재귀적인 연관 관계(overlapping subproblem structure)를 가지고 있다.
2. 최적 부분구조(optimal substructure)
- 최적화의 원리(principle of optimality)라고도 하며, 전체 문제의 해가 최적해(optimal solution)라면, 부분 문제의 최적해는 전체 문제의 최적해의 부분해여야 한다는 것을 말한다.
- 한 문제의 최적해는 부분문제의 최적해들로 구성된다.
최단 경로 문제를 보면, $V(i,j)$ 계산에 요구되는 최적해는 $V(i+1,j)$의 최적해와 $V(i,j+1)$의 최적해가 필요하다. 이해를 위해 다음과 같이 1에서부터 p까지의 최단 경로를 찾는 문제를 생각해보자. 여기서 파란색으로 나타낸 선은 해당 문제의 최적해를 나타낸다.

최단 경로에는 p가 포함되어 있다. 이때, 최적화의 원리란 p부터 n까지의 최단 경로라는 부분문제에서의 최적해는 1부터 p까지의 최적해의 일부인 파란실선이어야 한다는 것이다. 이를 간단히 증명해보자. 만약 초록색 선이 p부터 n까지의 최단 경로라면, 1부터 n까지의 최단 경로가 파란색 선이라는 가정에 위배된다. 왜냐하면 전체 문제의 최단 경로에 p가 포함되어 있기 때문이다. 다시 말해, 원래 문제인 1부터 n까지의 최단 경로인 파란색 선이라는 최적해의 부분해가 p부터 n까지의 최단 경로 문제의 최적해가 되어 principle of optimality를 만족한다.
그렇다면 이번에는 최장 경로 문제를 살펴보자. 최장 경로 문제는 중복방문을 허용하지 않으면서 가장 거리가 먼 경로를 찾는 문제를 말하는데, 아래 그림을 보자. 아래 그림에서는 화살표 옆에 해당 경로를 선택 시 발생하는 비용을 나타낸다.

(1 → 4)의 최장 경로를 찾는 것이 전체 문제라고 한다면, 이때의 최적해는 굵은 화살표로 표시한 (1 → 3 → 2 → 4)가 된다. 이때, 부분문제인 (1 → 3)의 최장 경로 문제를 보자. 이때 최적해는 (1 → 2 → 3)이므로 전체 문제의 최적해의 부분해(1 → 3)가 부분문제의 최적해가 되지 않는다. 즉, 동적계획법의 선행 조건인 최적화의 원리를 만족하지 않는다.
정리하면, 동적계획법은 여러 단계에 걸쳐 순차적으로 의사결정을 내리는 문제를 풀고자 하는 방법이다. 이때 문제는 중첩되는 부분문제들로 구성될 수 있는 구조로 이루어지고 전체 문제의 최적해의 부분해가 부분문제의 최적해를 만족하는 최적화 원리가 적용가능해야 한다. 이를 만족한다면, 내포된 부분문제와 이를 포함하는 부분문제 간 재귀식을 구성하고 순차적으로 해결함으로써 전체 문제를 해결한다.
도입 예시 2
순차적 의사결정문제의 예시를 살펴보자.
- 문제 상황
- 초기 자본 수준을 $x_0$라 하고, $x_1, x_2, \cdots, x_T$를 시점 $1, 2, \cdots, T$의 자본 수준이라고 하자.
- 시점 $t$에서 $a_t~ (0 \le a_t \le x_t)$를 쓰고 남은 돈을 투자하여 다음 시점 $t+1$초의 자본수준은 $x_{t+1} = \alpha(x_t - a_t), ~ \alpha>1$가 된다.
- $T$기간동안의 총 효용(utility) $U(a_0) + U(a_1) + \cdots + U(a_{T-1})$을 최대화하고자 한다. 이때 $U(0)=0$이며, $a>0$에 대해 $U^\prime(a) > 0$을 만족한다고 가정
- $U(a)=a$
문제 상황을 살펴보면 매 시점 사용하는 돈($a_t$)은 1) 현재 자본 수준($x_t$)에 의해 제약되고, 2) 이전 시점의 자본 수준($x_{t-1}$)과 지출($a_{t-1}$)의 영향을 받는다. 즉, 이전 단계의 의사결정이 다음 의사결정에 영향을 미치는 전형적인 순차적 의사결정문제다.
그럼, $T$기간동안의 총 효용(utility) $U(a_0) + U(a_1) + \cdots + U(a_{T-1})$을 최대화하는 매 시점의 지출 $a_t$를 동적계획법을 활용해 구하기 위해서 어떻게 문제를 구조화해야할까? 즉, 어떻게 해야 중첩되는 문제구조이면서 하위문제와 상위문제 간 문제구조를 구성할 수 있을까?
먼저 $t$시점에 $x_t$만큼의 자본 수준을 보유했다고 가정해보자. 그러면 남은 기간 $t+1, t+2 , \cdots$의 의사결정은 사실 이전 단계의 의사결정의 영향을 받지 않는다. 남은 기간 동안의 의사결정은 과거와는 오직 $t$시점에 $x_t$만큼의 자본수준을 보유한다는 사실에만 의존할 뿐이다. 즉, $x_t$만큼의 자본이 주어져있다는 사실이 정해지고 나면, 그 이전의 의사결정의 결과는 $x_t$에 흡수되어 있으므로 그 이후의 의사결정은 이전의 의사결정과는 독립적인 의사결정으로 볼 수 있다. 이러한 성질을 가지고 문제를 구조화해보자.
문제 구조화
1) $v_t(x)$ 함수 정의
$v_t(x)$ := $t$시점에서의 자본수준이 $x$일 때 $t$시점부터 남은 기간 동안의 총 효용의 최대값
위와 같이 정의한다면, 내가 관심있는 전체 문제는 $v_0(x_0)$로 나타낼 수 있다. 즉,
$v_0(x_0)$ = 초기상태부터 남은 기간 동안 얻을 수 있는 총 효용의 최대값
2) $\delta^*_{t}(x)$ 함수 정의
$\delta^*_{t}(x)$ := $t$시점에서의 자본수준이 $x$인 경우, 효용 최대화를 위한 지출 $a$
부분문제
- $T-1$ 시점
우선, 가장 작은 하위문제인 마지막 시점에서의 총 효용 최대화문제를 생각해보자. $v_t(x)$를 계산하기 위한 가장 하위문제는 $v_{T-1}(x)$다. (참고로 최단 경로 문제에서 가장 하위문제는 우측 하단에 해당하는 V(4,5)였다.)
$v_{T-1}(x)$ = 마지막 의사결정 단계의 총 효용의 최대값
이를 다시 나타내면 다음과 같다. (여기서, $U(a)=a$이기 때문에 선형증가함수다.)
$$v_{T-1}(x) = \underset{0 \le a_{T-1}\le x}{\operatorname{max}}{U(a_{T-1})} = \underset{0 \le a_{T-1}\le x}{\operatorname{max}}{a_{t-1}} = x$$
즉, 마지막 시점에서 얻을 수 있는 총 효용의 최대값은 $x$가 된다는 뜻이다.
가장 작은 하위문제에서의 $\delta^*_{T-1}(x)$는 다음과 같으며 $T-1$시점에서 자본수준이 $x$일 때 효용 최대화를 위해 $x$만큼의 지출이 필요하다는 의미를 담고 있다.
$$\delta^*_{T-1}(x) = x$$
정리하자면 가장 작은 부분문제인 마지막 시점 $T-1$에서의 총 효용의 최대값은 $v_{T-1}(x) = x$이며, 이때 총 효용을 얻기 위한 지출은 $\delta_{T-1}(x) = x$이다.
- $T-2$ 시점
이번에는 남은 두 기간 동안 총 효용을 최대화하는 문제를 생각해보자. 먼저 $T-2$ 시점에 자본수준이 $x$일 때 남은 두 기간 동안의 총 효용의 최대값 $v_{T-2}(x)$는 다음과 같다.
$$v_{T-2}(x) = \underset{\begin{array} 00\le a_{T-2}\le x \\ 0 \le a_{T-1} \le \alpha(x-a_{T-2})\end{array}}{\operatorname{max}}\{{U(a_{T-2}) + U(a_{T-1})\}}$$
이때, 이전 단계 $T-1$에서 돈이 $x$만큼 남았을 때 얻을 수 있는 총 효용의 최대값 $v_{T-1}(x)$를 계산했었다. 따라서, 이 문제는 다음과 같이 다시 쓸 수 있다. 편의를 위해 $a_{T-2}$를 $a$로 표현했다.
$$v_{T-2}(x) = \underset{0 \le a \le x}{\operatorname{max}}{\{U(a) + v_{T-1}{(\alpha(x-a))}\}}$$
위 식은 $T-2$ 시점에 $a$만큼 지출했을 때 얻을 수 있는 총 효용의 최대값을 의미한다. 즉, 어떤 $a$를 선택해야 총 효용을 최대화할 수 있을까? 라는 형태로 문제를 재정의했다. 다시 말해, $v$ 함수를 통해 부분문제들 간 재귀적 형태로 문제를 재정의했다. 이를 계산해보면,
$$v_{T-2}(x) = \underset{0 \le a \le x}{\max}{\{a + \alpha (x-a)\}}$$
$$ = \underset{0 \le a \le x}{\max}{\{ (1 - \alpha)a + \alpha x\}} = \alpha x$$
가 된다($\because {1-\alpha < 0}$). 즉, $T-2$ 시점의 자본수준이 $x$일 때, 남은 두 기간 동안의 총 효용의 최대값은 $\alpha x$다. 그리고 이때의 $a$는 0이므로,
$$\begin{array}vv_{T-2}(x) = \alpha x \\ \delta_{T-2}(x) = 0\end{array}$$
즉, $T-2$ 시점에서 자본수준이 $x$일 때, 지출이 없어야지만 총 효용이 $\alpha x$로 최대값을 갖는다.
- $T-3, T-4, \cdots$
위와 같은 과정을 나머지 시점에 대해서도 진행을 하면 다음과 같은 결과를 얻을 수 있다.
$$v_t(x) = \alpha^{T-t-1} x$$
$$\delta_{t}(x) = \begin{cases} 0, & t=0,1,\cdots,T-2 \\ x, & t=T-1\end{cases}$$
즉, $T-2$시점 이전까지는 자본수준이 $x$일 때 무조건 돈을 쓰지 않고 모두 투자한 뒤, 마지막 단계($T-1$)에서 자본수준이 $x$일 때 모든 돈을 지출하는 것이 총 효용을 최대화한다.
이때, $\delta$를 남은 기간 동안의 총 효용을 최대화하기 위해서 각 단계별로 어떤 의사결정을 내려야할지 알려주는 것을 의사결정 규칙(decison rule)이라고 한다.
(확정적) 동적계획법
위의 예는 전형적인 동적계획법에 해당하는 다단계의 순차적인 의사결정 문제에 해당한다. 동적계획법은 확정적 동적계획법과 확률적 동적계획법으로 나눌 수 있는데, 우선 확정적 동적계획법에 대해 살펴보자.
동적계획법이 다루는 문제는 순차적 의사결정 문제라고 언급했다. 이때, 의사결정은 행동(action)이라고도 부르며, 각 의사결정을 내리는 시점을 단계(stage) 혹은 의사결정시점(decision epoch)이라고 한다. 이때 의사결정자는 각 단계에서 갖고 있는 정보를 바탕으로 의사결정을 내리는데, 이처럼 의사결정을 하는 데 있어서 필요한 정보를 상태(state)라고 한다. 즉, 각 단계에서 상태를 바탕으로 의사결정이라는 행동이 이루어진다.
도입예시 2의 경우, 특정 시점에서 돈 사용량을 결정하고 나면, 다음 시점의 자본 수준이 결정되었다. 이처럼 한 단계에서 상태정보를 기반으로 의사결정을 하게 되면, 주어진 시스템의 상태가 현 단계에서 다음 단계의 다른 상태로 상태 전이(state transition)가 이루어진다. 이를 식으로 나타내면 다음과 같다.
$$s_{t+1} = f_t(s_t, a_t)$$
이때, 확정적(deterministic)이라는 의미는 현 상태에서 행동을 하고 나면 그 다음 단계의 상태가 확정적으로 결정이 된다는 뜻으로, 위 식에서 보면 $f()$라는 함수를 통해 다음 단계의 상태가 함수적으로 결정이 되고 있다.
무언가 의사결정을 하고 나면, 해당 의사결정을 평가하는 평가지표가 필요하다. 이를 위해 동적계획법에서는 각 단계에 보상(reward)이라는 개념을 도입한다. 즉, 어떤 상태에서 어떤 행동을 하면 그에 따른 보상을 받는데 이를 $r_t$로 정의한다.
$$r_t = r_t(s_t, a_t)$$
(도입예시 2의 경우)
- 상태(state): 각 시점에 보유한 자본수준
- 행동(action): 지출량
- 상태 전이: 지출량을 결정(행동)하고 나면, 다음 달 초기자본 수준 결정
- 보상(reward): 자본수준 $x$에서 $a_t$만큼 지출 시 U(a_t)만큼 효용 발생
아래 그림을 살펴보면 순차적 의사결정이라는 프레임워크는 다음과 같이 동작하며, 각 과정에서 문제해결($a$값 결정)이 이루어진다.
- 초기상태 $S_0$를 바탕으로 $a_0$라는 의사결정
- ($S_0$, $a_0$)의 결과로 보상 $r_0$
- ($S_0$, $a_0$)에 따라 다음 상태 $S_1$ 결정(상태 전이)
- 반복

그러면 어떤 평가기준을 가지고 각 단계에서 $a$라는 의사결정을 내려야할까? 일반적으로 사용되는 평가지표는 총 보상합이다. 즉 우리가 해결하고자 하는 문제를 정리하면 다음과 같다.
- 초기 상태 $s_0$가 주어졌을 때, $T$ 기간에 걸친 총 보상합을 최대화하기 위한 일련의 행동들($a_0, a_1, \cdots,a_{T-1}$을 결정하는 것
- 총 보상합
$$r_0 + r_1 + \cdots + r_{T-1}$$
- 의사결정 규칙(Decision rule): 각 단계에서 모든 가능한 상태에 대해, 최적의 행동을 찾는 것
$$\delta_t(s_t) = a_t$$
- 정책(Policy): 모든 단계에서의 의사결정규칙의 집합
$$\pi = \{\delta_t\}, t=0,1,\cdots,T-1$$
즉, $T$ 기간 동안의 총 보상합을 최대화할 수 있게끔, 각 단계에서 어떤 상태에서 어떤 행동을 취해야할지에 대한 최적의 행동인 의사결정 규칙의 집합, 정책을 찾아내는 것이 동적계획법의 목표이다.
중첩되는 부분문제들과 역진 귀납법(overlapping subproblems and backward induction)
그렇다면 순차적 의사결정 문제를 일반적으로 어떻게 구조화해야할까? 우선 특정 단계에서 한 상태가 주어져있다고 가정해보자. 그러면 이후 남은 단계들에서 이루어진 모든 의사결정은 현 단계 이전의 의사결정의 영향을 받지 않는다. 이를 독립성이라고 한다. 특정 단계에서 상태 정보가 명확하게 주어진다면, 이후 단계의 의사결정은 해당 정보만으로도 충분하다는 것이다.
이러한 독립성을 바탕으로 재귀적 문제들을 만들어낼 수 있는데, 다음과 같이 시점 $t$에서 $t$ 시점 이후의 총 보상합을 최대화하는 부분문제 $v^*_t(s_t)$를 정의해보자. 즉, 중첩되는 부분문제를 정의해보자.
$$v^*_t(s_t) = \underset{a_t, a_t+1, \cdots, a_{T-1}}{\max}{\{r_t + r_{t+1} + \cdots + r_{T-1}\}}$$
이때, 우리가 궁극적으로 구하고자 하는 문제는 $v^*_0(s_0)$가 된다.
위처럼 문제를 정의했을 때 중첩되는 문제를 만들어내는 과정은 다음과 같다. 먼저 가장 마지막 단계에서의 $v_{T-1}(s_{T-1})$을 정의하고, 그 다음 마지막 두 단계에서의 $v_{T-2}(s_{T-2})$를 정의한다. 같은 방식으로 정의를 해나가다 보면, $v_t(s_t)$는 $v_{t+1}(s_{t+1})$을 포함한 문제로 정의할 수 있다.

벨만 최적 방정식(Bellman Optimality Equation)
우리가 궁극적으로 풀고자하는 문제는 $t$ 시점에서 $s_t$라는 상태가 주어진 상황에서 $t$ 시점 이후 남은 기간 동안의 총 보상합을 최대화하기 위해 남은 기간동안 각 단계에서 어떤 의사결정(행동)을 내려야 할 것인가를 결정하는 것이다. 이때, $v_t$와 $v_{t+1}$은 어떠한 관계를 가지고 있다. 이를 벨만 최적 방정식이라고 한다.

위 식의 의미를 살펴보자. $s_t$라는 상태가 주어져 있는 상황에서 $t$시점부터 남은 기간 동안의 총 효용을 최대화하고자 한다($v^*_t(s_t)$). 상태 $s_t$에서 $a_t$라는 행동을 취하면 $r_t$라는 즉각적인 보상을 얻는다($r_t(s_t,a_t)$). 그 다음 이를 통해 다음 상태로 전이($t+1$)가 된다. $v_{t+1}$의 의미를 살펴보면, $t+1$부터 남은 기간 동안 얻을 수 있는 총 효용의 최대값이다. 따라서, 위 식의 의미는 $r_t(s_t, a_t) + v^*_{t+1}(f_t(s_t, a_t))$의 의미는 $t$ 시점에 $s_t$가 주어진 상황에서 $a_t$라는 action을 취했을 때 $t$시점부터 남은 기간 동안 얻을 수 있는 총 효용의 최대값이다. 그리고 $v_t$값은 $v_{t+1}$값을 활용하여 재귀적인 식을 도출해낼 수 있다.
여기서 최적화의 원리(principle of optimality)를 상기해보자. 즉, $v_t$가 포함된 $v_{t+1}$ 문제의 최적해를 활용하여 $v_t$의 최적해를 구하는 성질을 만족하는 경우에 벨만 방정식을 통해서 최적해를 찾아낼 수 있다.
이러한 벨만 최적 방정식을 해결하는 방법이 역진 귀납법(backward induction)이라는 방법론이다. 사실 이전 문제들(최단 경로 찾기, 도입예시2)을 모두 역진 귀납법으로 해결했는데, 작은 사이즈의 문제부터 순차적으로 풀어나가는 당연한 방법을 의미한다. 벨만 최적 방적식을 역진 귀납법을 활용하여 $v_{T-1}$부터 해결해야 한다는 것이다. 그런데 이때 주의해야할 점은 계산 과정에서 모든 가능한 상태에 대해 계산해야 한다는 것이다.


이번 장에서는 동적계획법에서 적용할 수 있는 일반적인 문제해결 방법론을 공부했다. 즉, 동적계획법에서는 중첩되는 부분문제의 구조를 활용하고, 최적화 원리를 만족하는 벨만 최적 방정식을 통해 문제를 해결해 나아가면 순차적인 의사결정 문제들을 효율적으로 해결할 수 있다.
'Reinforcement Learning > 강화학습의 수학적 기초와 알고리듬 이해' 카테고리의 다른 글
| Week6. MDP-2 (0) | 2022.04.03 |
|---|---|
| Week5. MDP-1 (0) | 2022.04.01 |
| Week4. 마르코프 과정 (0) | 2022.03.31 |
| Week3. 동적계획법2 (0) | 2022.03.29 |
| Week1. 강화학습의 이해 (0) | 2022.03.23 |



